O Git é o standard da indústria quando se fala em controlo de versões. Se já alguma vez pesquisaram sobre isto, já devem ter lido que permite “voltar ao passado” do nosso código, permitindo regressar a versões anteriores, voltar à versão atual, programar em paralelo, etc.
No curso, a grande maioria utiliza o Git em conjunto com o GitHub. Por estarem tão interligados no nosso workflow, por vezes é difícil distinguir o que é que é Git e o que é que é GitHub. Algo que também acontece é usarmos o Git e GitHub como uma simples plataforma de partilha de código, em que nós fazemos push e os nossos colegas fazem pull, não sendo, provavelmente, a melhor maneira, é bem melhor do que partilhar os ficheiros por Facebook Messenger e ter de lidar manualmente com o que mudou entretanto.
Este guia visa clarificar o que são o Git e o GitHub e como devem ser utilizados, dando exemplos práticos desde a instalação do Git à programação em paralelo via GitHub. O guia está feito para ser acompanhado num ambiente Unix (seja em Mac ou numa distribuição Linux), que é o que aconselhamos para quem está a aprender. Sendo cross-platform, o Git também funciona no Windows e não terás qualquer problema em seguir este guião nesse SO. Apesar de haver aplicações gráficas para usar Git, vamos usar exclusivamente o terminal Depois de aprenderes, está à vontade para usar qualquer aplicação gráfica que gostes; é mais fácil passar do terminal para um ambiente gráfico do que o contrário.
A primeira parte, Git Basics, é um tutorial de Git que não assume qualquer conhecimento prévido da plataforma. Se já te sentes confortável com o Git e só pretendes aprender como melhorar o workflow do teu grupo, podes passar diretamente para a secção GitHub - Working remote.
![]()
Git Basics
Git is a free and open source distributed version control system designed to handle everything from small to very large projects with speed and efficiency.
‘nough said.
Por agora, vamos esquecer o distributed e vamos assumir que o Git é local, ou seja, instalamo-lo no nosso PC e utilizamo-lo só nós, e só nos nossos projetos. Mais tarde falaremos do trabalho em equipa.
Instalar e configurar
A instalação é simples, basta correr o comando apropriado à vossa distribuição:
Ubuntu/Mint:
$ sudo apt install git
Manjaro/Arch Linx:
$ sudo pacman -S git
Nota: Na instalação em Windows, podes aceitar as opções recomenddas. Aproveita é para trocares o editor de texto default para o teu favorito, assim poderás, mais abaixo, ignorar essa configuração.
Depois de instalado, convém fazer uma pequena configuração que consiste em identificarem-se ao Git:
$ git config --global user.name "Your Name Comes Here"
$ git config --global user.email you@email.com
Nota: Isto serve para o Git identificar o código que submeteram como vosso, mas expõe o vosso email se colocarem o vosso repositório online e o tornarem público.
Podem também alterar o editor de texto do Git com o comando
$ git config --global core.editor "nome_do_editor"
em que nome “nome_do_editor” é o nome que usariam para abrir o editor de texto através do terminal. Por exemplo, para definir o Visual Studio Code, o comando seria
$ git config --global core.editor "code"
Aviso para os utilizadores de Windows: Para seguir este guia, deverás usar a Git Bash. A Git Bash é um emulador de bash para Windows e é instalado automaticamente com o Git. Se usares a Git Bash, deves poder seguir o tutorial tal e qual como está.
Repositórios
No Git trabalha-se em repositórios. O vosso código pertence a um repositório e todas as alterações que lhe façam são registadas dentro desse repositório.
Os repositórios são criados manualmente e um repositório deve corresponder a um e só um projeto.
Para criar um repositório, devem fazê-lo dentro na raíz do projeto.
Por exemplo, eu tenho um projeto de LI3 que estou a começar, guardado em ~/dev/li3. O projeto já tem alguns ficheiros de código e eu quero criar um repositório Git para me ajudar daqui para a frente:
$ cd ~/dev/li3
$ ls
enunciado.pdf include src
Criar um repositório é simples:
$ git init
Initialized empty Git repository in /home/miguel/dev/li3/.git/
Como se pode observar pelo output do comando, o Git criou a diretoria .git na raíz do meu projeto. É uma diretoria oculta, pelo que não aparece no output do ls, temos de passar uma opção para ver ficheiros ocultos:
$ ls
enunciado.pdf include src
$ ls -a
. .. enunciado.pdf .git include src
Felizmente, nunca vamos precisar de a usar. A diretoria .git é para uso exclusivo do Git: é onde ele guarda todas as informações relativas ao vosso repositório. Não lhe devemos mexer. Toda a interação com o Git será feita via linha de comandos.
Agora que eu tenho o meu repositório criado, posso ver qual o estado dele:
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
enunciado.pdf
include/
src/
nothing added to commit but untracked files present (use "git add" to track)
Vamos dissecar o output:
Commits
O Git está-me a dizer que os ficheiros enunciado.pdf, include/ e src/ estão untracked. Para o Git, os ficheiros ou estão tracked ou untracked: um ficheiro tracked é, como o nome indica, um ficheiro que o Git monitoriza, ou seja, em que regista as alterações que lhe são feitas. Por defeito, qualquer ficheiro novo num repositório é untracked por defeito e tem de explicitamente tracked.
Nota: Podem ter reparado que include/ e src/ não são, na verdade, ficheiros: são diretorias, como evidenciado pelo sufixo /. Com esta sintaxe, o Git está-nos a dizer que todos os ficheiro naquelas diretorias (e possíveis sub-diretorias) estão untracked.
Também fala em commits. Diz-me que ainda não tenho commits (No commits yet) e que não tenho nada para fazer commit (nothing added to commit). Mas o que é um commit?
Um commit é um estado; é um “game save”; é uma versão do código. Um commit guarda o estado de um projeto a uma certa altura. Quando fazemos um commit, estamos a dizer ao Git para tirar um snapshot a como o código está naquele momento e o guardar para sempre. É com base nesta mecânica que podemos iterar entre versões do nosso projeto: quando um projeto tem vários commits, tem vários estados no tempo, permitindo-nos “voltar atrás” e ver/recuperar versões anteriores do código. Mas, mais para a frente, falaremos melhor disto.
Voltando ao output de há bocado:
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
enunciado.pdf
include/
src/
nothing added to commit but untracked files present (use "git add" to track)
Como o Git sugere, podemos fazer track dos ficheiros usando git add <file>:
$ git add src
Neste caso, fiz track dos ficheiros em src/. Se voltar a ver qual o estado do repositório
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: Makefile
new file: src/interface.c
new file: src/main.c
new file: src/program
new file: src/sort.c
Untracked files:
(use "git add <file>..." to include in what will be committed)
enunciado.pdf
include/
posso ver que todos os ficheiros em src/ serão adicionados no próximo commit como novos ficheiros. Mas falta-me adicionar os restantes ficheiros. Posso adicionar todos com um simples comando:
$ git add .
Num ambiente Unix, o . simboliza a diretoria atual. Assim, estou a indicar ao Git que quero adicionar tudo o que está dentro da minha diretoria.
O estado do repositório é, agora:
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: enunciado.pdf
new file: include/common.h
new file: include/dataSimples.h
new file: include/date.h
new file: include/estrutura.h
new file: include/interface.h
new file: include/list.h
new file: include/pair.h
new file: include/sort.h
new file: include/user.h
new file: Makefile
new file: src/interface.c
new file: src/main.c
new file: src/program
new file: src/sort.c
Boa! Tenho tudo adicionado, estou pronto para fazer o meu primeiro commit, certo?
Não.
Bom, tecnicamente, sim. Não há nada que nos impeça de fazer um commit agora. No entanto, como tudo no mundo da informática, também o Git tem um conjunto de boas práticas que devem ser seguidas. Uma delas é evitar adicionar ficheiros binários. Num repositório, só devem ser adicionadas as sources; não se deve adicionar os binários gerados por essas sources.
No meu caso, tenho dois ficheiros binários: o relatorio, o binário do meu programa, gerado pela Makefile, e enunciado.pdf, o enunciado do meu trabalho.
Assim sendo, vou removê-lo dos ficheiros a que quero fazer commit. O Git diz-me como o fazer: (use "git rm --cached <file>..." to unstage)
git rm --cached enunciado.pdf src/program
Agora, o estado do repositório é
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: include/common.h
new file: include/dataSimples.h
new file: include/date.h
new file: include/estrutura.h
new file: include/interface.h
new file: include/list.h
new file: include/pair.h
new file: include/sort.h
new file: include/user.h
new file: Makefile
new file: src/interface.c
new file: src/main.c
new file: src/sort.c
Untracked files:
(use "git add <file>..." to include in what will be committed)
enunciado.pdf
src/program
Estou pronto para fazer o commit! Um commit contém uma mensagem que descreve o que é que o código daquele commit faz: que funcionalidade implementa ou que bug resolve, etc. Essa mensagem é constituída por um assunto (obrigatório) e um corpo (opcional).
Um commit é feito com um comando simples:
$ git commit
Este comando abre o editor de texto default do sistema, onde podemos escrever a mensagem. O assunto é escrito primeiro, seguido do corpo, separados por uma linha vazia:
Isto é o assunto
Isto é o corpo
# Isto é um comentário, vai ser ignorado e não vai ser incluído no corpo da mensagem
No entanto, a grande maioria das vezes, o assunto da mensagem é suficiente. Se for esse o caso, podemos utilizar antes o comando
$ git commit -m "O assunto aqui"
que não abre o editor de texto e faz imediatamente o commit.
Para o meu repositório, vou executar o comando git commit -m "Init". Visto que este é o meu primeiro commit utilizo uma mensagem que simbolize que estou a inicializar o repositório com código pré-existente.
Nota: Também há boas práticas a seguir na escrita de mensagens: devem ser claras e escritas na mesma língua usada no código, ou seja, de preferência, em Inglês. O corpo da mensagem deve ser usado para descrever o quê e o porquê do commit de uma forma mais detalhada, não o como. O assunto deve ser capitalizado (a primeira letra deve ser uma maiúscula) e não deve acabar com um ponto final. O assunto também deve ser escrito no modo imperativo, ou seja, deve fazer sentido quando colocado na frase This commit will …, por exemplo: Boa mensagem: Add data structure to represent Person Má mensagem: Added data structure
Agora o estado do meu repostório é
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
enunciado.pdf
src/program
nothing added to commit but untracked files present (use "git add" to track)
Ignorar ficheiros
O Git continua a avisar que o enunciado.pdf e o src/program não estão tracked. Mas eu não quero que eles sejam adicionados. Felizmente, o Git permite-nos criar um ficheiro na raíz do repositório onde podemos especificar que ficheiros é que queremos que o Git ignore: o .gitignore.
Vamos criar um. No ficheiro, só temos de especificar o caminho do ficheiro que queremos ignorar:
$ cat .gitignore
enunciado.pdf
src/program
# Isto é um comentário
O Git reconhece o ficheiro e ignora o que lhe dissemos, identificando também que o .gitignore ainda não é tracked.
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
nothing added to commit but untracked files present (use "git add" to track)
Vou fazer o commit deste novo ficheiro:
$ git add .
$ git commit -m "Add .gitignore"
$ git status
On branch master
nothing to commit, working tree clean
Boa! Os binários estão a ser ignorados e não há nada que ainda não esteja representado num commit.
Mas e se agora eu guardar outro ficheiro PDF na raíz do repositório e mais um binário em src/?
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
enunciado2.pdf
src/program2
nothing added to commit but untracked files present (use "git add" to track)
Teria de modificar o meu .gitignore e adicionar o nome dos ficheiros novos… Ou posso generalizar, alterando o meu .gitignore para
$ cat .gitignore
*.pdf
src/program
Assim, qualquer ficheiro no meu repositório cujo nome termine em .pdf é automaticamente ignorado! Mas como ignorar todos os binários em src/ se eles não têm uma extensão? A forma mais fácil é, simplesmente, alterar a Makefile para os gerar noutra diretoria e ignorar todo o seu conteúdo! Depois de criar a diretoria bin/ e alterar a Makefile , o estado do repositório é
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: .gitignore
modified: Makefile
Untracked files:
(use "git add <file>..." to include in what will be committed)
bin/
no changes added to commit (use "git add" and/or "git commit -a")
Como previsto, bin/ aparece como untracked. O program e o program2 já não aparecem, porque, como pertencem a bin/, já estão representados, embora ocultos.
Para ignorar todo o conteúdo da diretoria, inclusivamente as suas possíveis subdiretorias, altero o meu .gitignore para
$ cat .gitignore
*.pdf
bin/
Agora, o estado é
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: .gitignore
modified: Makefile
no changes added to commit (use "git add" and/or "git commit -a")
Assim, ignoramos com sucesso os binários e PDFs que temos e que possamos vir a adicionar. Agora, basta fazer o commit:
$git add .
$git status
On branch master
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
modified: .gitignore
modified: Makefile
$ git commit -m "Move binaries to 'bin/' and ignore 'bin/' and all PDFs"
Nota: Esta não é uma boa mensagem de commit. O assunto é um pouco longo (58 caratéres) e ligeiramente confuso de ler. Mas o problema não é a forma como a mensagem foi escrita, mas a forma como o commit foi estruturado: os commits devem representar uma única alteração ao funcionamento, independentemente do número de ficheiros alterados para fazer essa alteração. Neste caso, fizemos duas alterações ao funcionamento: mudar a geração dos binários para bin/ e ignorar a diretoria e ignorar todos os PDFs. A mensagem ficou mal em consequência de termos feito num commit o que deveria ter sido feito em dois.
Navegar entre commits
Agora que já temos alguns commits, podemos executar
$ git log
commit bed65eefe12d19d26c9a7a2ac847245982eba007 (HEAD -> master)
Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
Date: Sun Mar 22 12:10:53 2020 +0000
Move binaries to 'bin/' and ignore 'bin/' and all PDFs
commit a582641704c87d0912355aba9cfa189613c56cac
Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
Date: Sun Mar 22 11:34:18 2020 +0000
Add .gitignore
commit ed10169a2ed0fe5b7aa756f501665d925cb5dd10
Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
Date: Sun Mar 22 11:22:52 2020 +0000
Init
para ver o histórico dos commits. Como podemos ver, os commits são identificados por uma hash única e contêm a informação da data em que foram criados e do seu autor. Também nos é mostrada a sua mensagem para fácil identificação do que é que o commit faz.
Nota: Para identificar um commit pode-se usar a hash completa, mas basta usar os primeiros 7 caratéres.
Usando estas hashes, podemos ver diferenças entre o estado atual e o de um determinado commit (neste exemplo, o commit ‘Init’) com
$ git diff ed10169
diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000..89ab085
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,2 @@
+*.pdf
+bin/
diff --git a/Makefile b/Makefile
index e4fe0a5..b2d8630 100755
--- a/Makefile
+++ b/Makefile
@@ -19,7 +19,7 @@ $(ODIR)/%.o : %.c $(DEPS)
$(CC) $(CFLAGS) -c -o $@ $<
program: $(SOURCES_OBJ) $(MY_LIBS_OBJ)
- $(CC) $(CFLAGS) $(wildcard $(ODIR)/*.o) $(wildcard $(OLDIR)/*.o) -o program $(LIBS)
+ $(CC) $(CFLAGS) $(wildcard $(ODIR)/*.o) $(wildcard $(OLDIR)/*.o) -o bin/program $(LIBS)
clean:
rm obj/*.o
ou, quando usado sem uma hash (git diff), as diferenças entre o estado atual e o último commit ou, quando usado com duas hashes (git diff ed10169 a582641), as diferenças entre esses dois commits.
Também podemos voltar, temporariamente, a um commit anterior (neste caso, o primeiro, ‘Init’) com
$ git checkout ed10169
usando
$ git checkout master
para regressar.
Reverter commits
Por qualquer razão, podemos ter reverter algo que foi feito. Sem Git, esta seria capaz de desgastar o CTRL-Z de qualquer teclado, isto se tivermos a sorte do histórico ainda estar acessível pelo ‘Undo’.
Podemos estar, por exemplo, a meio de implementar uma funcionalidade em que alteramos vários ficheiros e apercebermo-nos de que não é uma boa implementação e querermos apagar. Sem Git, teríamos de encontrar e apagar todo o código manualmente ou utilizar o sempre presente CTRL-Z em todos os ficheiros, rezando para que não apaguemos acidentalmente qualquer outra parte importante.
No Git, podemos simplesmente reverter o estado para o último commit. As alterações que eu fiz ao meu repostiório consistiram em alterar alguns ficheiros e adicionar uns novos, que ainda estão untracked.
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: src/interface.c
modified: src/main.c
Untracked files:
(use "git add <file>..." to include in what will be committed)
src/dataSimples.c
src/estrutura.c
src/lib/
no changes added to commit (use "git add" and/or "git commit -a")
Como estão untracked, eu sei que são ficheiros novos e que, portanto, não estavam em qualquer commit anterior, podendo eliminá-los, manualmente, com confiança. Os restantes ficheiros, como já existem num commit anterior e econtram-se no estado modified, podem simplesmente ser revertidos como o Git nos indica: (use "git restore <file>..." to discard changes in working directory).
Como eu quero reverter tudo, executo
$ git restore .
Assim, os meus ficheiros voltaram ao estado original.
Mas e se eu já tiver feito commit do que quero reverter? Nesse caso, posso usar git revert. Este comando vai criar “anti-commits”, ou seja, commits inversos aos que queremos apagar. Para este exemplo, criei um commit para apagar, o commit db13e27:
$ git log
commit db13e27b66e5020ae73991ea89d3cd2dd15dab90 (HEAD -> master)
Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
Date: Sun Mar 22 13:23:24 2020 +0000
Commit a apagar
commit bed65eefe12d19d26c9a7a2ac847245982eba007
Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
Date: Sun Mar 22 12:10:53 2020 +0000
Move binaries to 'bin/' and ignore 'bin/' and all PDFs
[...]
Para o apagar, faço
$ git revert db13e27
Removing src/test.c
[master 0ec1358] Revert "Commit a apagar"
1 file changed, 0 insertions(+), 0 deletions(-)
delete mode 100644 src/test.c
e aceito a mensagem pré-definida que o Git escreve para o commit inverso. Consultando
$ git log
commit 0ec1358f0af1a8be7e8d2f1191bffe368b7b6585 (HEAD -> master)
Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
Date: Sun Mar 22 13:25:39 2020 +0000
Revert "Commit a apagar"
This reverts commit db13e27b66e5020ae73991ea89d3cd2dd15dab90.
commit db13e27b66e5020ae73991ea89d3cd2dd15dab90
Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
Date: Sun Mar 22 13:23:24 2020 +0000
Commit a apagar
commit bed65eefe12d19d26c9a7a2ac847245982eba007
Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
Date: Sun Mar 22 12:10:53 2020 +0000
Move binaries to 'bin/' and ignore 'bin/' and all PDFs
posso ver que, apesar do resultado do meu commit ter sido apagado (o ficheiro que criei já não está no repositório), a história mantém-se e posso, se quiser, reverter a reversão.
Aviso: É por isto que é importante ter uma boa disciplina quando se trata de criar commits. Se trabalharmos em várias funcionalidades ao mesmo tempo, sem fazer commit conforme as vamos acabando, esta vantagem do Git é inutilizável porque também iríamos apagar código que queremos manter.
Nota: Há muitas mais formas de utilizar o revert e ainda mais de reverter commits. Algumas mantêm a história de commits, outras não. Algumas pessoas consideram mau não manter a história, outras consideram necessário para manter o histórico de commits limpo e legível (geralmente em projetos grandes). Esta resposta no StackOverflow explica outras formas de reverter commits.
Branches
Os branches são uma ferramenta muito poderosa. Todos os repositórios contêm, no minímo, um branch, o master, o default branch.
Podemos ver em que branch estamos fazendo
$ git status
On branch master
nothing to commit, working tree clean
Obviamente, como ainda não criamos nenhum branch, estamos no master.
Para criar um branch chamado branch1, podemos executar
$ git branch branch1
Para ver que branches existem, executamos
$ git branch
branch1
* master
em que o branch com o asterisco é o branch em que nos encontramos.
Para mudar de qualquer branch para branch1, utilizamos
$ git checkout branch1
Switched to branch 'branch1'
e, consequentemente, para voltar para o master fazemos
$ git checkout master
Switched to branch 'master'
Também podemos, ao mesmo tempo, criar um branch e mudar para lá:
$ git checkout -b branch2
Switched to a new branch 'branch2'
Mas o que é um branch, afinal? Um branch é uma linha de desenvolvimento independente. Quando criamos um branch, ocorre uma bifurcação (fork) no histórico do repositório: a linha de desenvolvimento é dividida em duas, independentes, em que o commit inicial do novo branch é o commit do branch original a partir do qual o novo branch foi criado. Confuso, certo?
Neste momento, o que temos é isto:
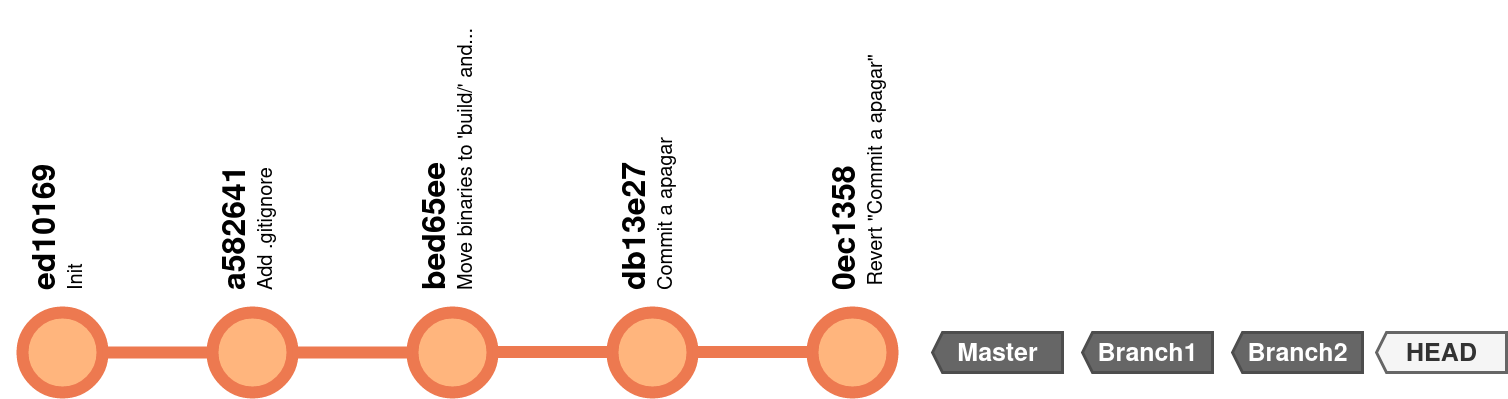
Cada nodo é um commit, e a etiqueta de um branch aponta para o nodo (commit) em que esse branch está.
Neste momento, todos os branches estão no mesmo commit, visto que ainda não criamos nenhum commit em nenhum branch desde que os criamos. Vamos alterar isso:
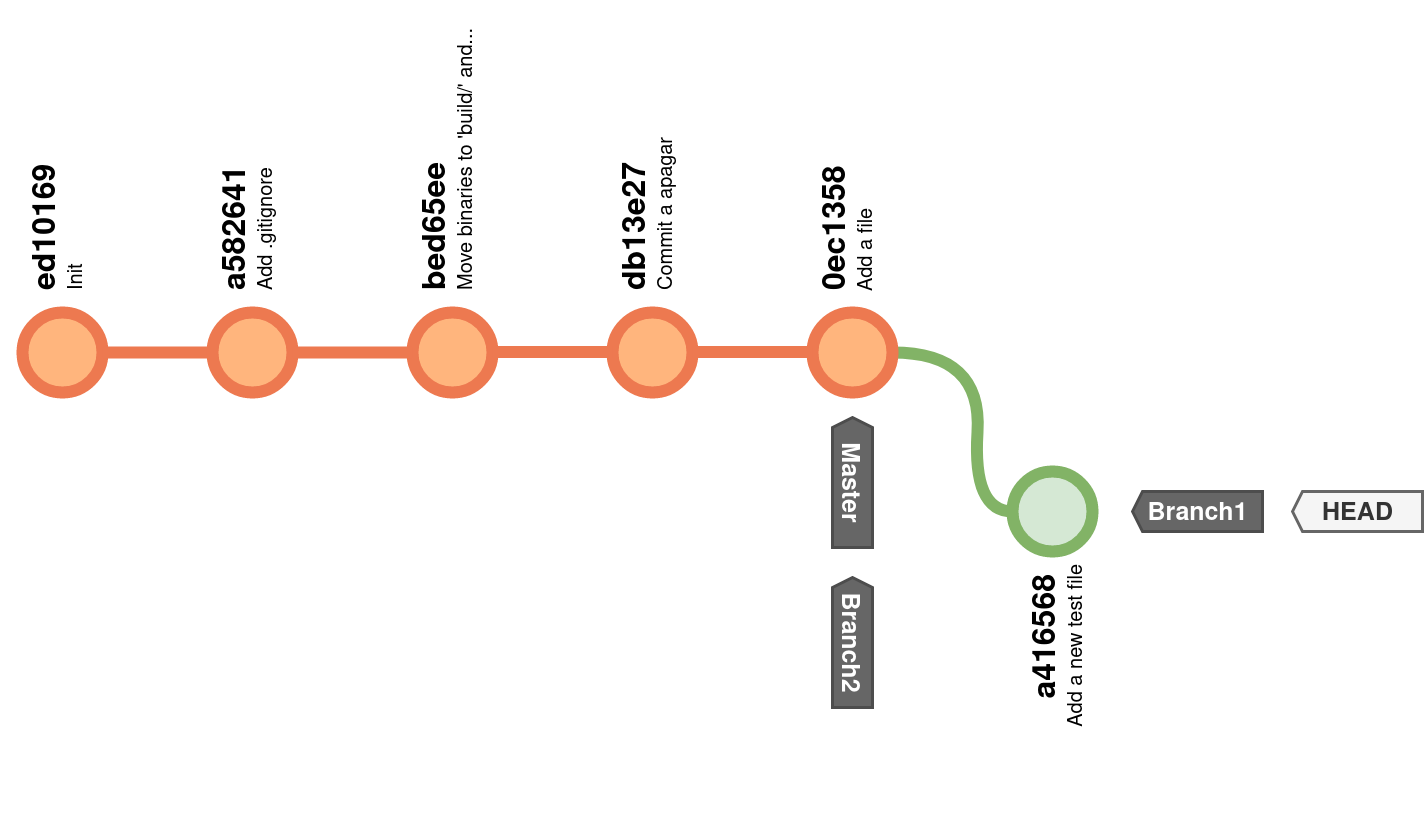
$ git checkout branch1
$ vim um_ficheiro.c
$ git status
On branch branch1
Untracked files:
(use "git add <file>..." to include in what will be committed)
um_ficheiro.c
nothing added to commit but untracked files present (use "git add" to track)
$ git add .
$ git commit -m "Add a new test file"
[branch1 a416568] Add a new test file
1 file changed, 0 insertions(+), 0 deletions(-)
create mode 100644 um_ficheiro.c
Agora, este é o histórico do repositório:
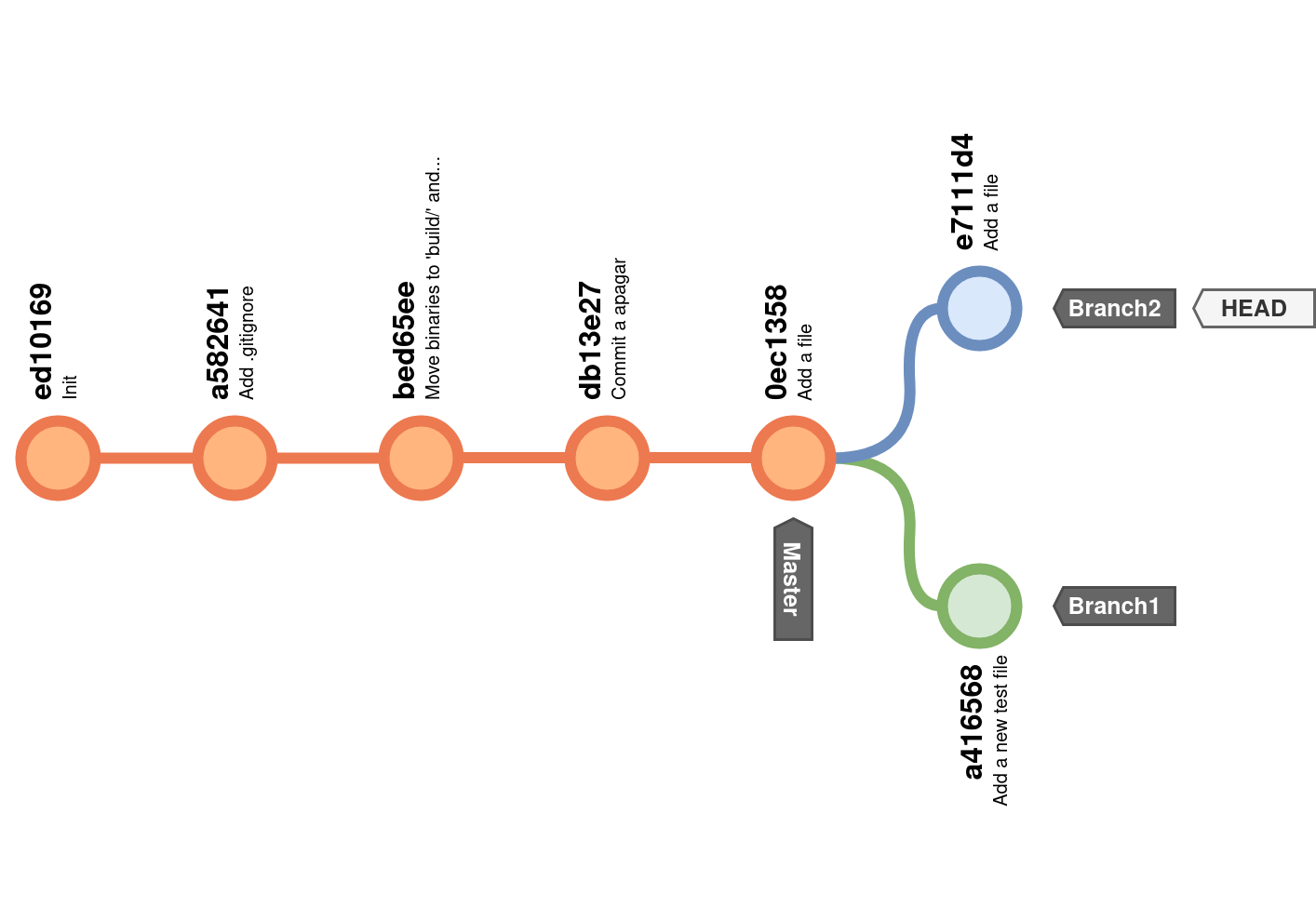
E se fizer outro commit, mas desta vez no branch2, com um ficheiro com o mesmo nome mas, em vez de vazio, com algum conteúdo?
$ git checkout branch2
$ vim um_ficheiro.c
$ cat um_ficheiro.c
algum conteudo
$ git add .
$ git commit -m "Add a file"
[branch2 e7111d4] Add a file
1 file changed, 1 insertion(+)
create mode 100644 um_ficheiro.c
O histórico do repositório fica assim:
Nota: Como já podem ter reparado, HEAD aponta para onde estivermos no histórico. Se fizermos git checkout ed10169 (Init), HEAD apontará para esse commit.
Agora, vou voltar para o branch1, alterar o documento um_ficheiro.c e fazer commit:
$ git checkout branch1
[alterar documento]
$ cat um_ficheiro.c
#include <stdio.h>
int main(){
printf("Hello World!");
return 0;
}
$ git add .
$ git commit -m "Add Hello World"
[branch1 d1c55cb] Add Hello World
1 file changed, 6 insertions(+)
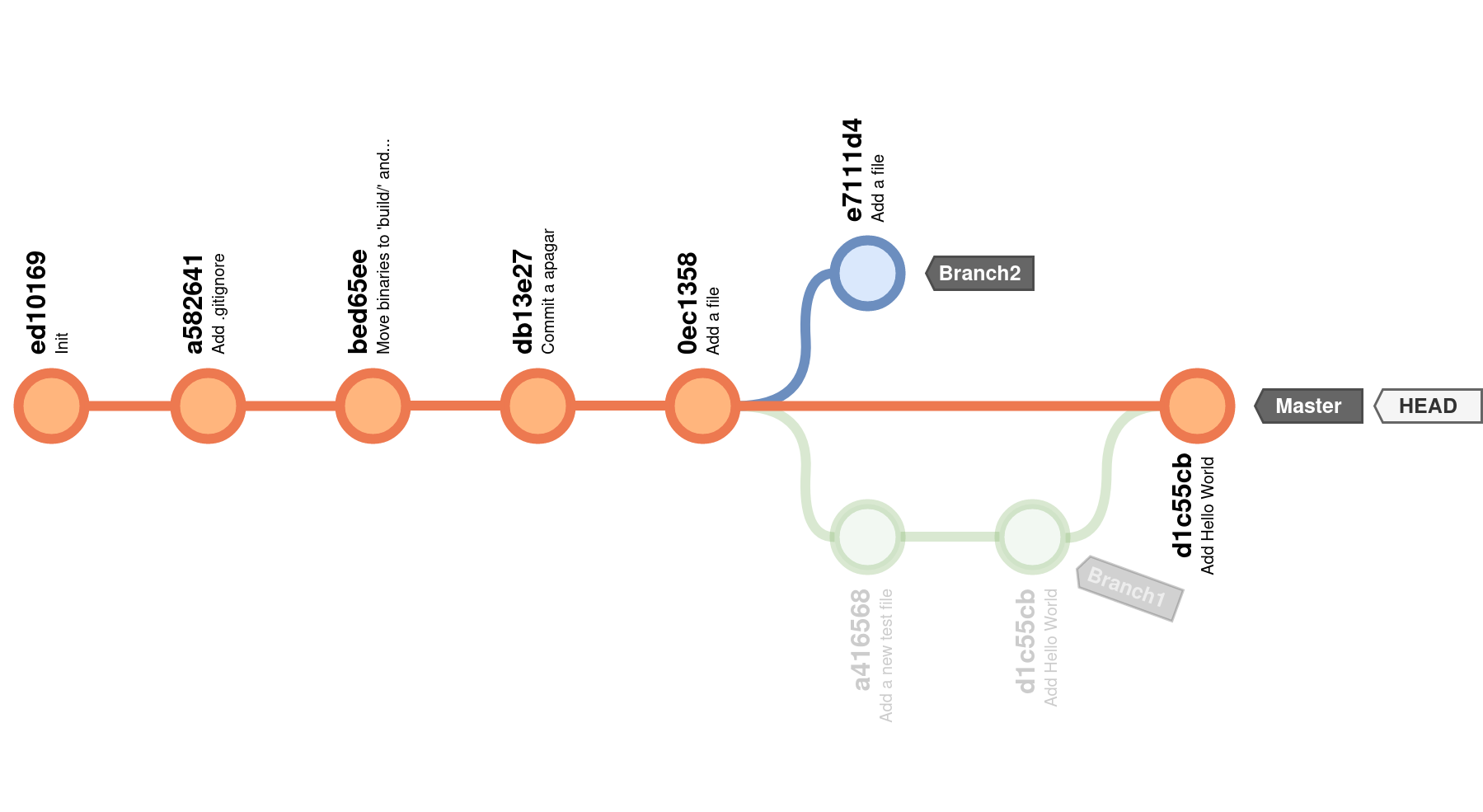
Mas agora quero colocar as alterações que fiz no branch1 no master. Quero fazer o merge de branch1 com o master. Para isto, temos de, primeiro, mudar para o branch para onde queremos “mandar” as alterações, neste caso o master. De seguida, ordenamos o merge com branch1 com o comando git merge:
$ git checkout master
Switched to branch 'master'
$ git merge branch1
Updating 0ec1358..d1c55cb
Fast-forward
um_ficheiro.c | 6 ++++++
1 file changed, 6 insertions(+)
create mode 100644 um_ficheiro.c
Como não vamos precisar mais do branch1, podemos apagá-lo com git branch -d branch1.
O gráfico do histórico do repositório agora está assim (o branch1 está semi-transparente para representar que já não existe):
Por último, quero fazer o merge do branch2 para o master. Como já estou no master, basta fazer
$ git merge branch2
CONFLICT (add/add): Merge conflict in um_ficheiro.c
Auto-merging um_ficheiro.c
Automatic merge failed; fix conflicts and then commit the result.
E… Houve problemas. Mais especificamente, houve um conflito. Quando o Git tenta juntar dois branches, ele faz um auto-merge: vê as diferenças entre os branches e junta-os harmoniosamente. No entanto, por vezes, o Git não sabe como fazer a junção, resultando num conflito. Um conflito pode ocorrer por várias razões. No nosso caso, criamos um ficheiro com o mesmo nome nos branches branch1 e branch2, mas cujo conteúdo era diferente. O Git não sabe se deve manter o conteúdo do ficheiro do master (que era o do branch1) ou o conteúdo do ficheiro do branch2, ou se deve subsituir um pelo outro, ou se deve juntar o conteúdo dos dois, etc. Para isso, temos de intervir e resolver o conflito manualmente. Para isso, temos de abrir o ficheiro num editor de texto (ou IDE):
<<<<<< HEAD
#include <stdio.h>
int main(){
printf("Hello World!");
return 0;
}
======
algum conteudo
>>>>>> branch2
Como podemos ver, o ficheiro está marcado com sintaxe do Git: entre <<<<<< HEAD e ====== está o conteúdo do nosso ficheiro; entre ====== e >>>>>> branch2 está o conteúdo deles. Aqui, nosso e deles referem-se aos branches. nosso refere-se branch em que estamos, neste caso o master, deles refere-se ao branch que está a ser incluído, neste caso o branch2.
Neste conflito, por ser um mero exemplo, foi, arbitráriamente, escolher manter o conteúdo do master. Para isso, basta eliminar tudo o que não for conteúdo do master, incluindo as marcações do Git:
#include <stdio.h>
int main(){
printf("Hello World!");
return 0;
}
Com o ficheiro corrigido, basta fazer um commit.
$ git status
On branch master
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add <file>..." to mark resolution)
both added: um_ficheiro.c
no changes added to commit (use "git add" and/or "git commit -a")
$ git add .
$ git commit
[master 843a289] Merge branch 'branch2'
Nota: Como este commit resulta de um merge, não defini a minha mensagem e aceitei a que o Git me propõs.
O histórico final do repositório fica
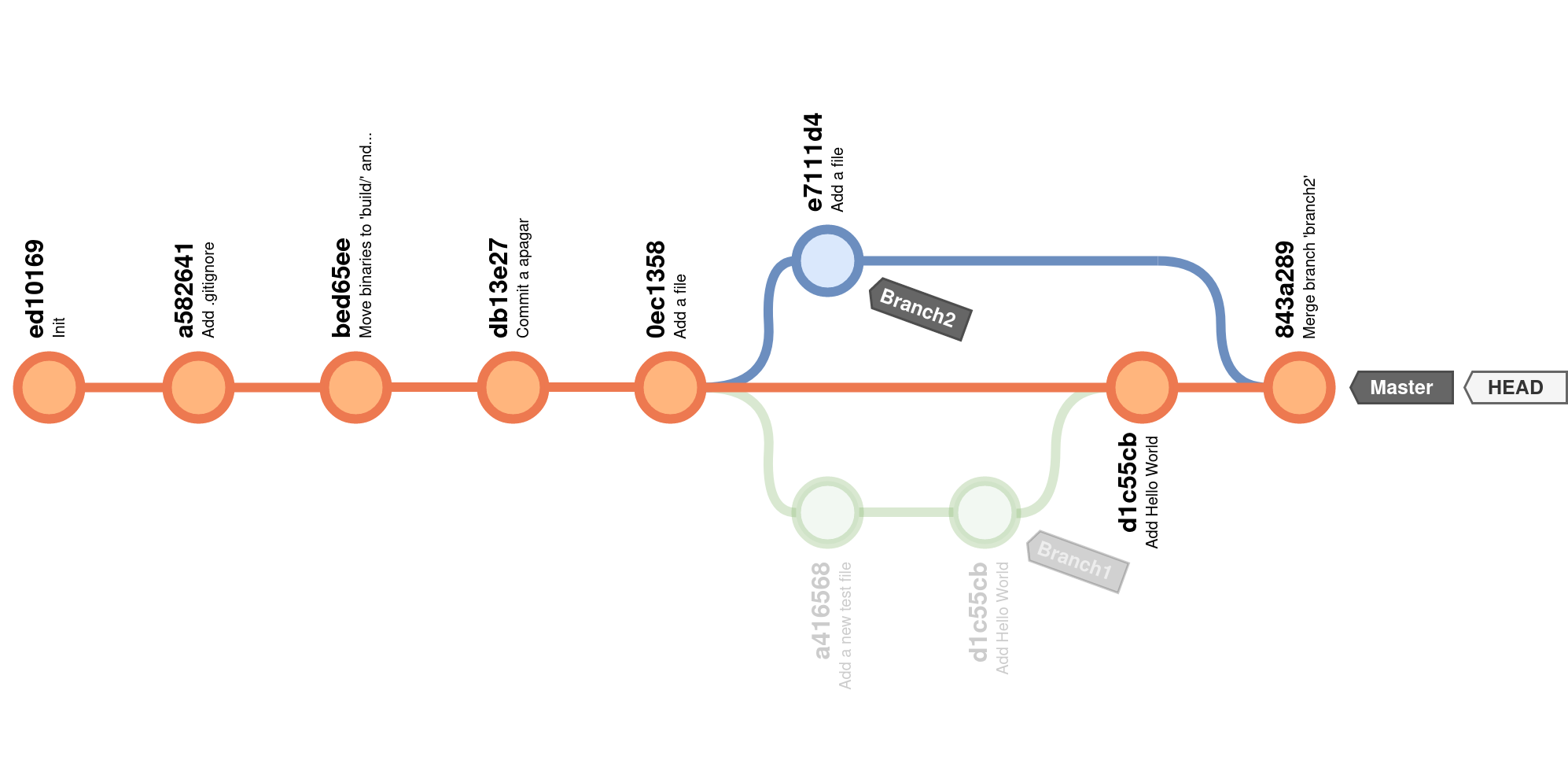
Podemos ver um esquema parecido a partir do Git:
$ git log --graph
* commit 843a2893407150a66d2a2bab93107ad27760f89a (HEAD -> master)
|\ Merge: d1c55cb e7111d4
| | Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
| | Date: Sun Mar 22 16:35:58 2020 +0000
| |
| | Merge branch 'branch2'
| |
| * commit e7111d4d2f101c55cb5d6d2c5ed5fd855bec6fd3 (branch2)
| | Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
| | Date: Sun Mar 22 15:29:28 2020 +0000
| |
| | Add a file
| |
* | commit d1c55cb0b3997724ab70b9aca9a2fc4117d456e0
| | Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
| | Date: Sun Mar 22 15:44:53 2020 +0000
| |
| | Add Hello World
| |
* | commit a416568514b37f0275b263213637fdaf56b45f2a
|/ Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
| Date: Sun Mar 22 15:06:50 2020 +0000
|
| Add a new test file
|
* commit 0ec1358f0af1a8be7e8d2f1191bffe368b7b6585
| Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
| Date: Sun Mar 22 13:25:39 2020 +0000
|
| Revert "Commit a apagar"
|
| This reverts commit db13e27b66e5020ae73991ea89d3cd2dd15dab90.
|
* commit db13e27b66e5020ae73991ea89d3cd2dd15dab90
| Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
| Date: Sun Mar 22 13:23:24 2020 +0000
|
| Commit a apagar
|
* commit bed65eefe12d19d26c9a7a2ac847245982eba007
| Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
| Date: Sun Mar 22 12:10:53 2020 +0000
|
| Move binaries to 'bin/' and ignore 'bin/' and all PDFs
|
* commit a582641704c87d0912355aba9cfa189613c56cac
| Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
| Date: Sun Mar 22 11:34:18 2020 +0000
|
| Add .gitignore
|
* commit ed10169a2ed0fe5b7aa756f501665d925cb5dd10
Author: CeSIUM <pedagogico@cesium.di.uminho.pt>
Date: Sun Mar 22 11:22:52 2020 +0000
Init
que nos mostra uma representação parecida com as imagens que temos visto, mas claro, sem o branch1, visto que foi apagado.
Nota: Há mais formas de fazer um merge. Geralmente, essas formas diferem em como é feita a gestão do histórico de commits e a prevenção/resolução de conflitos. Sugiro que pesquises sobre git squash e git rebase.
Os branches são uma ferramenta muito poderosa porque permitem programar de forma “concurrente”. Podemos ter um branch principal, habitualmente o master que contenha a versão estável do nosso software, enquanto o desenvolvimento é feito noutros branches. Assim, podemos ter, por exemplo, um branch por cada grande funcionalidade a implementar e trabalhar em várias ao mesmo tempo, sem misturar os seus commits facilitando imenso a reversão, por exemplo. Depois, quando funcionalidade é acabada, o seu branch é merged com o master e eliminado.
![]()
GitHub - Working remote
Parabéns por teres chegado aqui! Esta secção vai ser muito mais breve! Agora que já sabes os básicos de Git, vamos falar sobre a parte remote do Git e onde é que o GitHub entra.
Na introdução, falamos que o Git é um distributed version control system. A verdade é que, apesar do Git ser muito útil para ser utilizado individualmente, é ainda melhor para trabalhar em equipa, suportando vários tipos de workflow.
O Git suporta remotes, ou seja, servidores remotos com Git configurado que guardam uma cópia do repositório. Isto permite a distribuição do código (não há um ponto central de falha) e permite que várias pessoas acedam ao mesmo repositório e tenham cópias do mesmo repositório.
Estando em MIEI, não deves ser estranho ao GitHub. Até já deves ter uma conta PRO. Se não, aproveita a oferta, é grátis para alunos universitários.
O GitHub é uma plataforma de hospedagem de source code que usa o Git. Ou seja, serve como um remote para repositórios Git.
Criar um repositório
Para um projeto, há três formas de ter um repositório no GitHub:
- se ainda não tivermos começado o projeto, podemos criar um repositório inicializado na plataforma e depois clonar o repositório para o nosso PC (a forma mais fácil)
- se já tivermos começado o projeto no nosso PC e pretendermos adicionar Git e colocar no GitHub, podemos fazer a mesma coisa que o ponto anterior e, depois de clonado, copiar o código para o repositório e fazer o primeiro commit.
- se já tivermos comçado o projeto no nosso PC que já seja um repositório, criamos um repositório vazio no GitHub e adicionamo-lo como remote ao nosso repositório local.
Ponto 1
Criar um repositório remote antes de começar um projeto é a forma mais fácil de o fazer. Basta entrar no GitHub, e clicar em New.
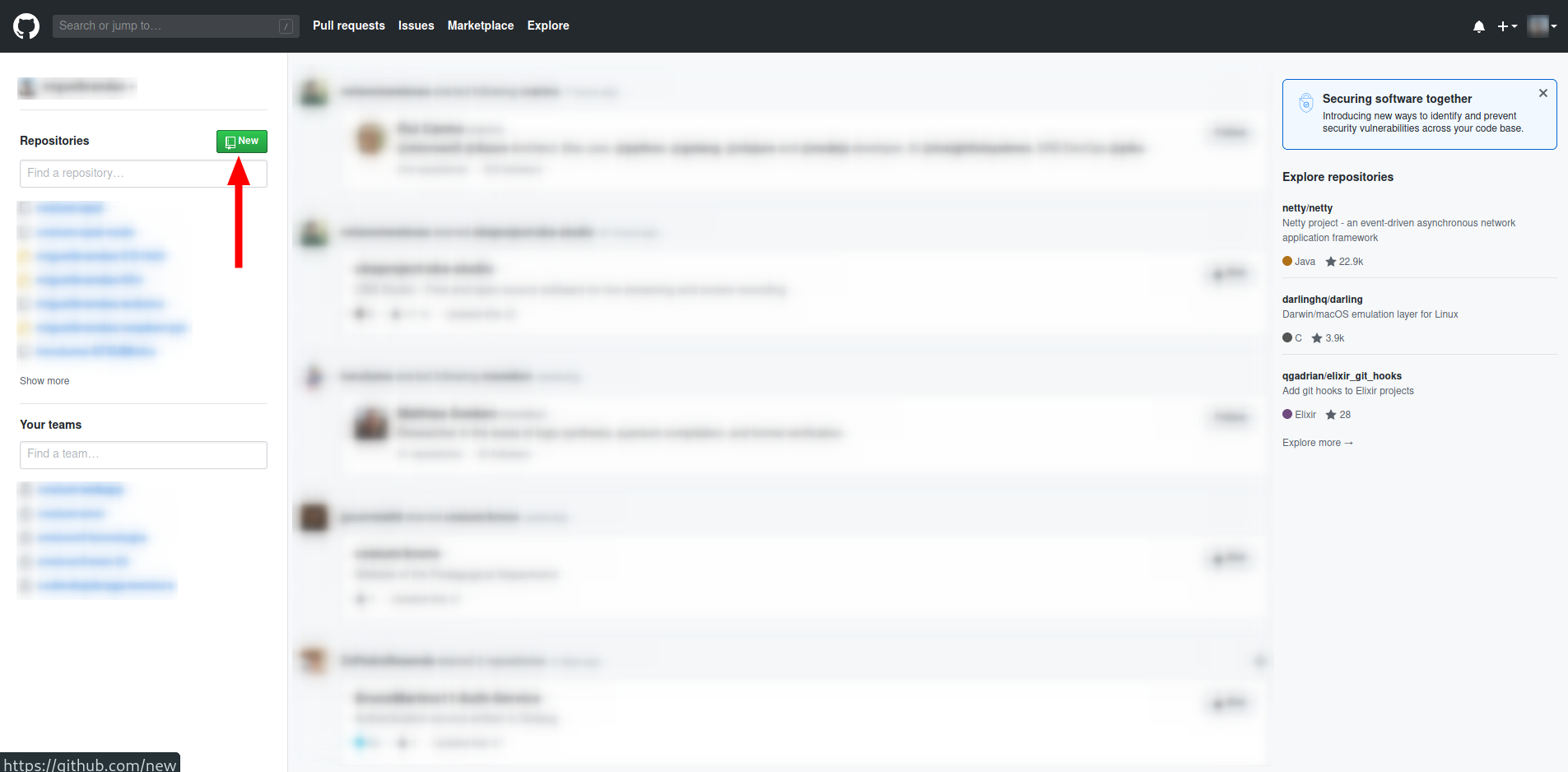
Na página que se abre, escolhemos o nome do repositório, escrevemos, opcionalmente, uma descrição e se queremos que seja público ou privado.
Como pretendemos clonar o repositório para o computador, inicializar com o README. Também temos a opção de escolher inicializar o repositório com um .gitignore pré-definido: dependendo da tecnologia que vamos usar no projeto, pode dar bastante jeito escolher começar com um .gitignore genérico para essa linguagem e irmos adaptando conforme necessário. Podemos também escolher uma licença. Se não escolhermos nenhuma, as leis normais dos direitos de autor aplicam-se. O botão informativo ao lado liga a esta página, que explica todos os detalhes de escolher, ou não, uma licença.
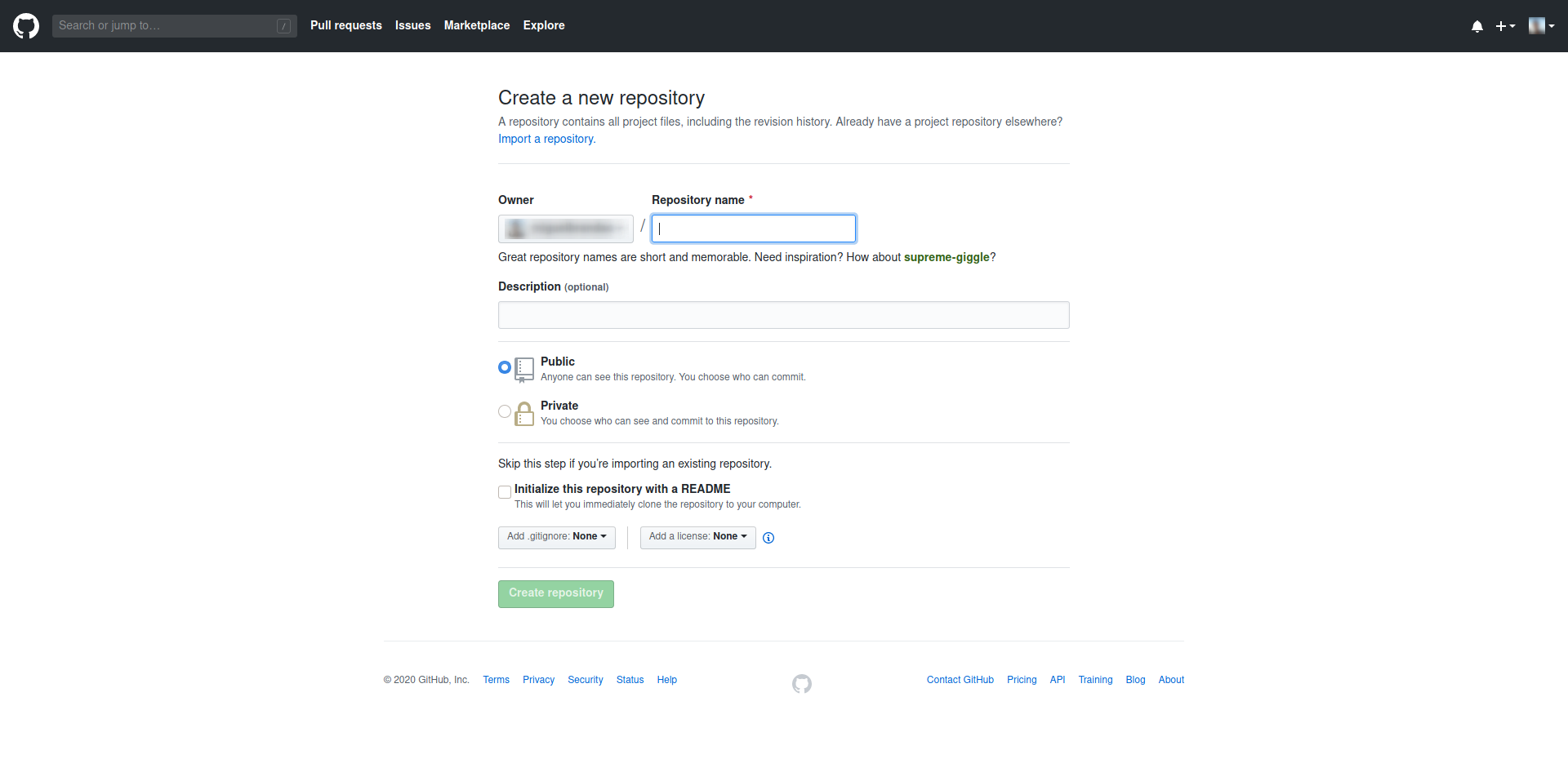
Depois, é só clicar no botão de clonar, copiar o link, abrir um termainal na diretoria onde queremos ter o repositório e executar o comando git clone <link>, substituindo <link> pelo link que copiamos. Se o repositório for privado, o Git pedir-nos-á as nossas credenciais de acesso ao GitHub: o username e a password.
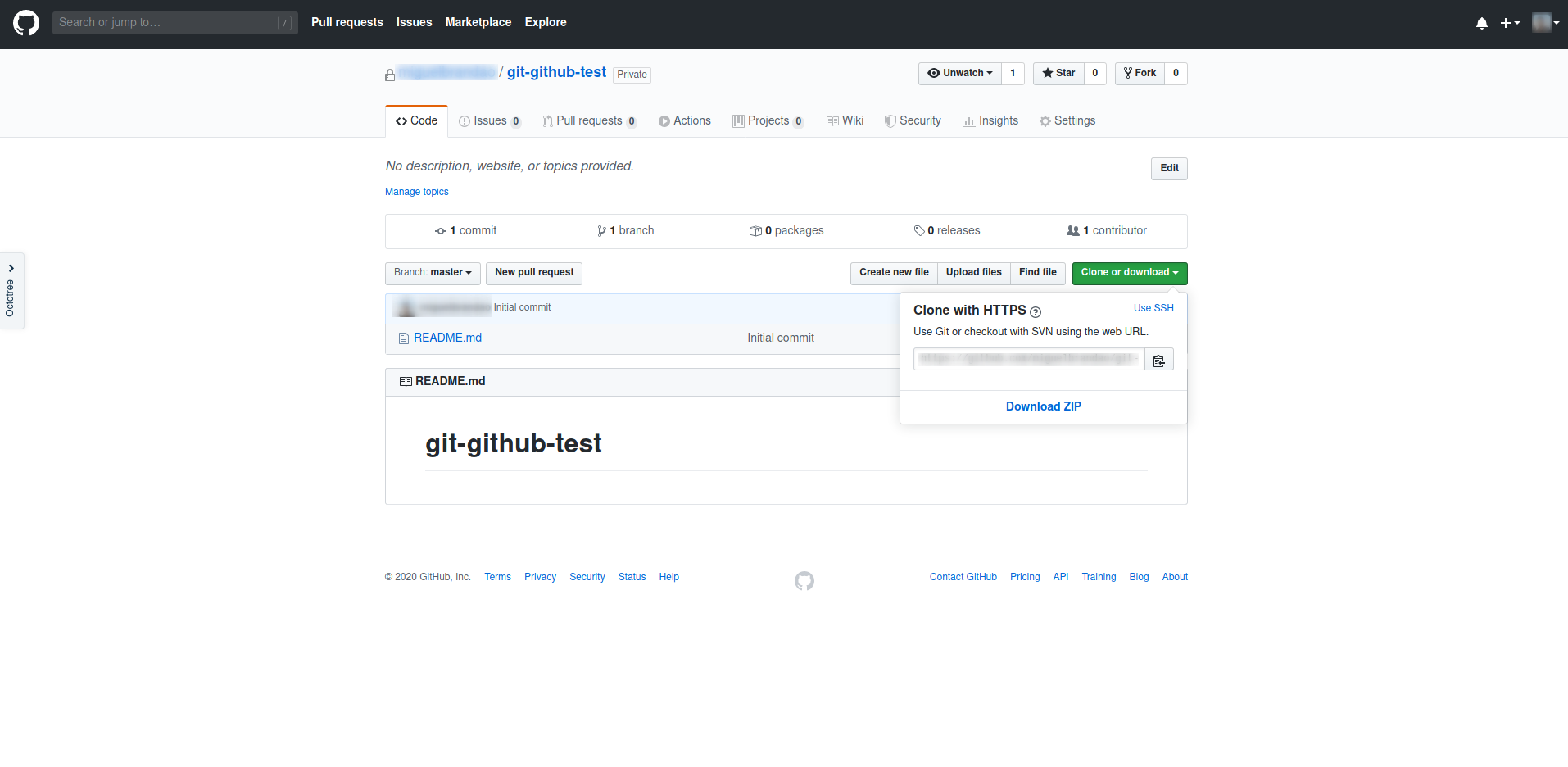
O repositório está pronto a ser usado! A sua diretoria tem o mesmo nome que o repositório no GitHub. Vamos ver como tirar partido do GitHub mais à frente.
Ponto 2
É idêntico ao Ponto 1. A única diferença é que, no fim do repositório ser clonado, temos de copiar o nosso código para o repositório e fazer o commit.
Ponto 3
Neste cenário, já temos um projeto local que queremos colocar no GitHub. Fazer como no ponto 2 é possível, mas nada, mesmo nada é recomendado, pois perde-se todos os branches, histórico do repositório e outra informação do repositório.
O processo é parecido com o do ponto 1. A única diferença na criação do repositório é que não o podemos inicializar, pelo que não podemos escolher criar o README, adicionar um .gitignore pré-defindo ou uma licença. No entanto, tudo isto pode ser feito manualmente, à posteriori.
Depois de criado, copiamos o link.
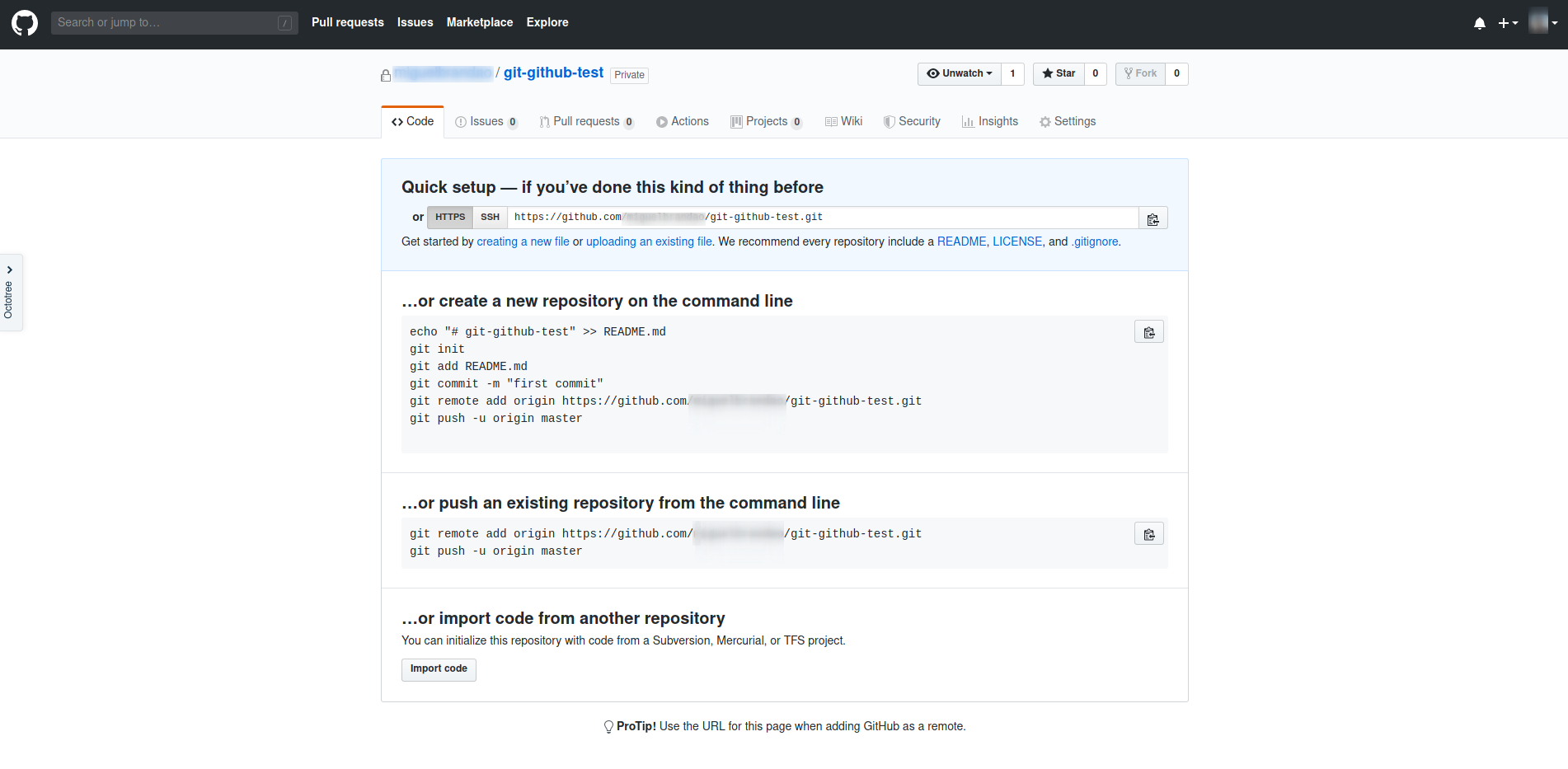
No nosso repositório local no branch master, executamos o comando
git remote add origin https://github.com/user/git-github-test.git
Este comando adiciona um remote ao nosso repositório, chamado (por convenção) origin.
De seguida, executamos o comando
git push --set-upstream origin master
Este comando faz duas funções: git push envia o branch atual (neste caso, o master) para o remote. No entanto, o nosso remote (o repositório que acabamos de criar no GitHub) ainda não tem nenhum branch. Portanto, temos de associar o branch local a um branch no remote. É isso o que faz --set-upstream origin master: define que o branch local master deve ser enviado para o branch master do remote origin.
Nota: Sempre que queremos fazer o push de um branch novo, temos de fazer git push --set-upstream origin <nome_do_branch>, para criar a associação entre o branch local e o seu remote. Os pushes consequentes desse branch podem ser feitos correndo apenas git push.
O repositório está pronto a ser usado!
Push, Pull e Fetch
Para utilizar um remote, há três comandos a saber: git pull, git fetch e git push.
Push
Já falamos um pouco do push: utiliza-se para atualizar o remote com os novos commits do branch ativo.
Pull
O git pull faz o download dos novos dados remotos e, de seguida, integra esses dados nos ficheiros ativos, ou seja, faz o merge. Por fazer merge, pode resultar em conflitos.
Seguindo o repositório de exemplo estabelecido na secção de Git Basics, um colega fez push de um branch branch3. No meu repositório local, posso executar
$ git pull
Enter passphrase for key '/home/miguel/.ssh/id_rsa':
remote: Enumerating objects: 5, done.
remote: Counting objects: 100% (5/5), done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 4 (delta 0), reused 4 (delta 0), pack-reused 0
Unpacking objects: 100% (4/4), 1.01 KiB | 344.00 KiB/s, done.
From github.com:miguelbrandao/git-github-test
* [new branch] branch3 -> origin/branch3
Already up to date.
Neste exemplo, o pull apenas fez o download do novo branch, pois era a única diferença entre o nosso repositório e o remote. Como o branch, para nós, é novo, não causou conflitos.
Fetch
O git fetch apenas faz o download dos novos dados remotos. É útil para poder ver o que aconteceu no remote sem ter de fazer a integração.
Trabalhar em equipa
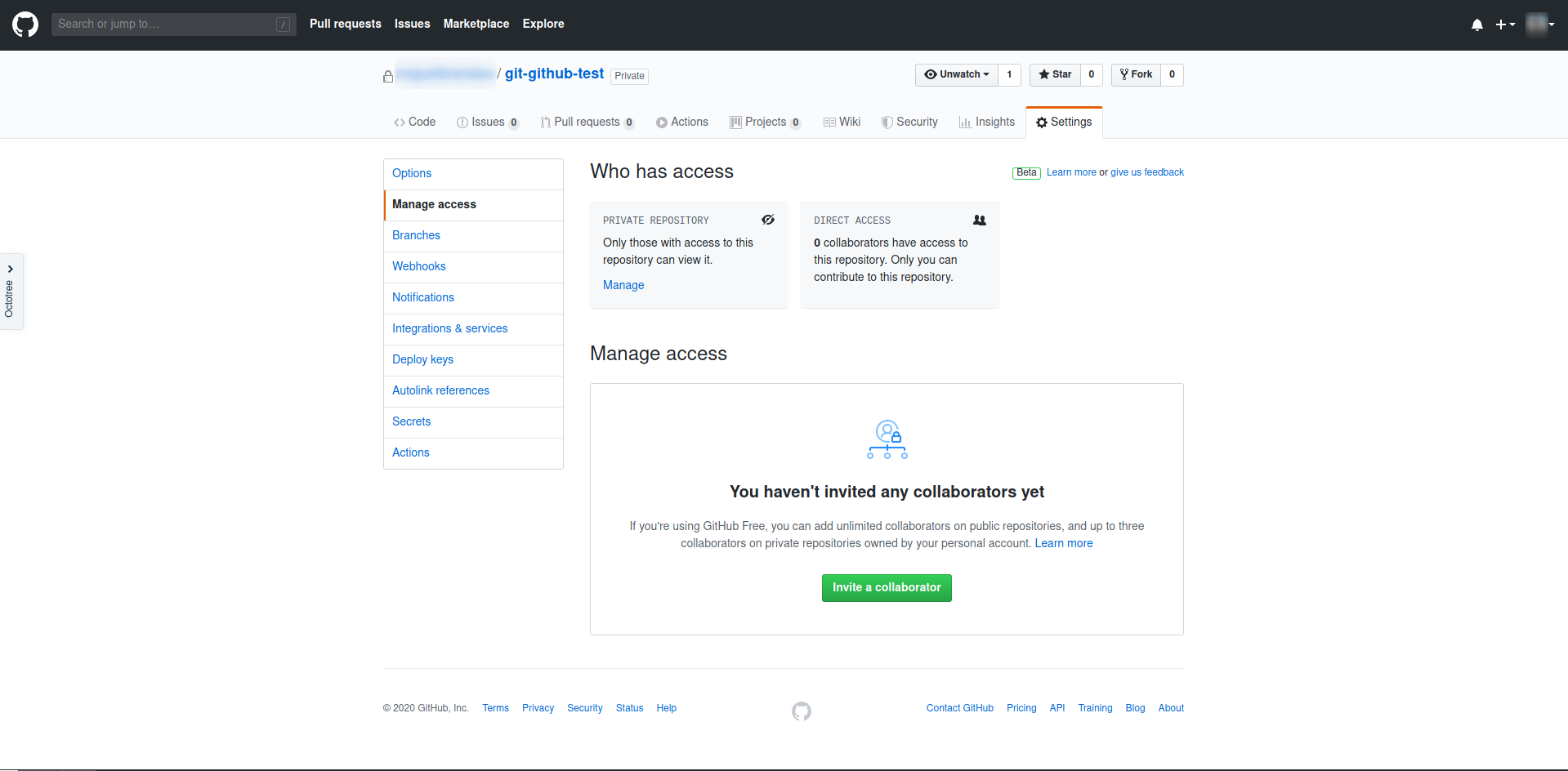
Se para um trabalho de grupo tiveres, no GitHub, um repositório privado (o que deves ter, pelo menos enquanto não és avaliado, por razões óbvias), precisas de dar permissões aos teus colegas para acederem ao teu repositório e poderem fazer pushes e pulls.
Tal é feito no separador Settings, em Manage Access. Para convidar um colaborador, basta clicar no botão, escrever o username do teu colega (que também precisa de ter uma conta no GitHub) e esperar que ele receba um email e aceite o convite.
Depois de teres convidado os teus colegas, têm de definir um workflow. Como é que vão fazer os pushes para o remote e sincronizar o código entre vocês?
Uma solução básica é simplesmente trabalharem a partir do master. Ou seja, toda a gente trabalha num único branch, o master. Todos os commits de toda a gente são feitos para o master, e cada um, antes de fazer push, faz pull do master, resolve os possíveis conflitos e faz push. Funciona, mas pode correr mal. O que vai acontecer, muito provavelmente, é que vai ficar um esparguete de commits e vai ser muito difícil qualquer roll-back que se tenha de fazer. Além disso, fica bastante mais difícil saber que ficheiros e linhas é que um colega alterou.
Outra solução é utilizarem branches: por cada funcionalidade criam um branch, podendo até colocar como prefixo, no nome do branch, as iniciais do colega responsável por aquela funcionalidade. Assim, cada um tem o seu branch e pode ir fazendo pushes sem ter de se preocupar com conflitos. Quando a funcionalidade for acabada ou acharem necessário, podem fazer o merge para o master. Assim, reduzem a quantidade de vezes que têm de lidar com conflitos.
Pull Requests (PRs)
No entanto, a melhor solução é usarem os Pull Requests. Um Pull Request, tal como o nome indica, é um pedido para fazer pull. Quando um colega submete um Pull Request, está a pedir ao resto do grupo para reverem e aceitarem as alterações que ele fez ao código. Desta forma, a equipa sabe sempre quais as alterações feitas e tem mais facilidade a analisar a qualidade do código.
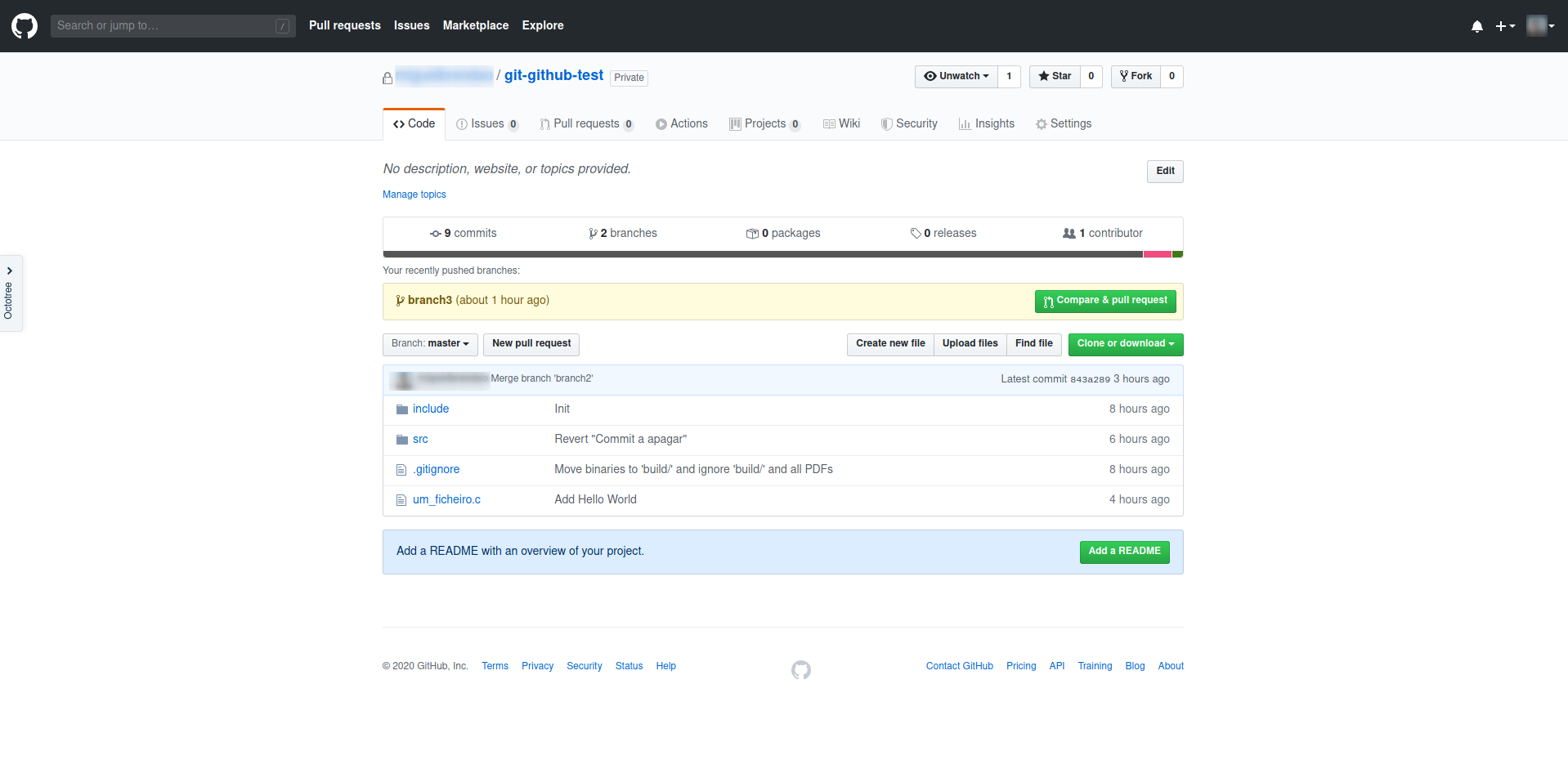
Nesta solução, como na anterior, o master reúne o trabalho acabado de toda a equipa. Por cada funcionalidade, é criado um branch. Quando o responsável por um branch achar que está pronto a ser merged com o master faz push do branch para o remote e cria um Pull Request.
Criar um Pull Request de um branch recentemente enviado é fácil: basta ir ao gitHub do repositório e clicar no botão Compare & pull request. O GitHub assume, por defeito, que queres fazer um Pull Request do teu branch para o master.
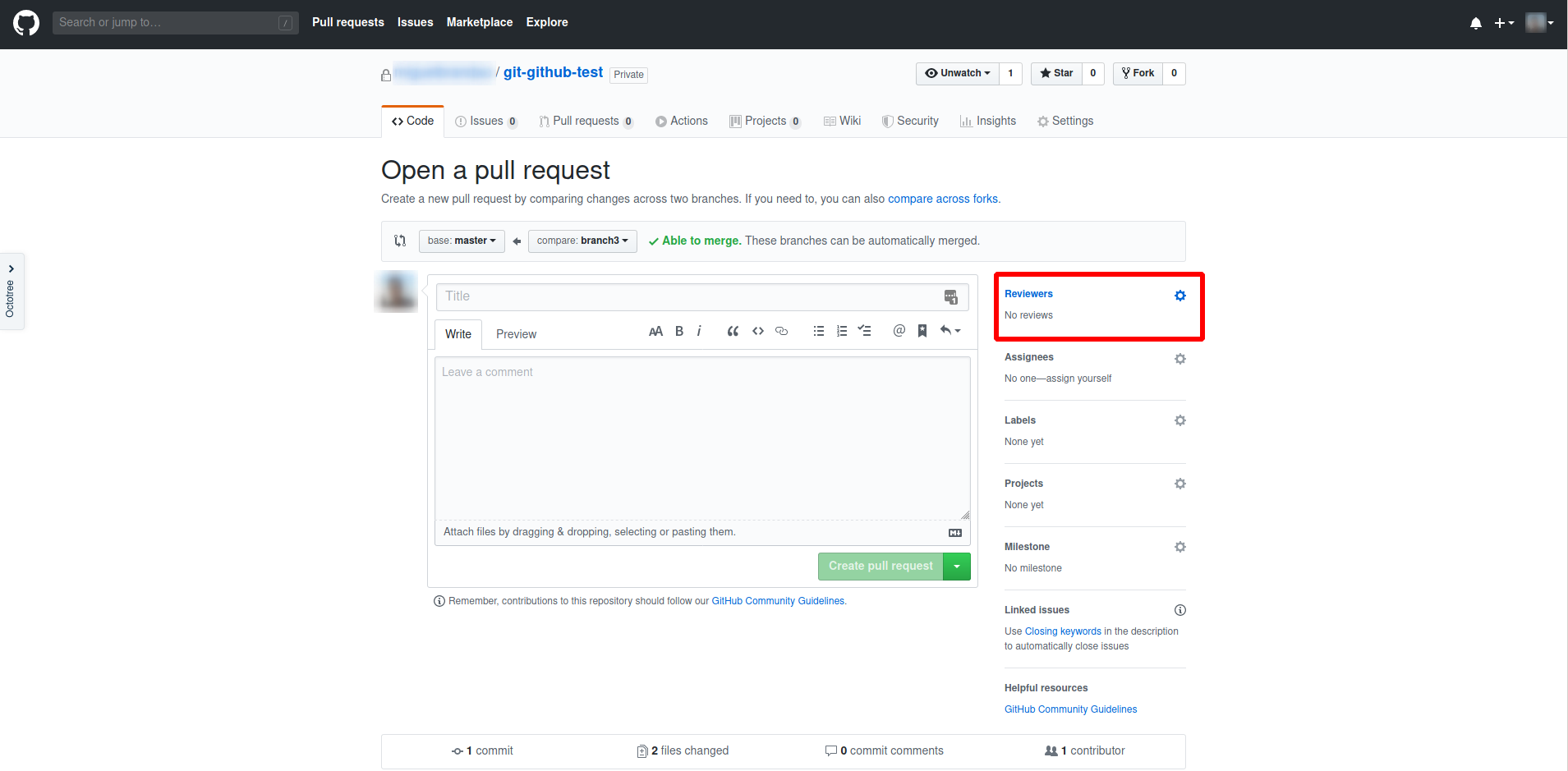
De seguida, basta preencher o título, ou usar o pré-definido pelo GitHub, escrever um comentário, opcionalmente, e escolher Reviewers, o que notificará os colegas escolhidos que fixeste um Pull Request e precisas de uma Review.
Enquanto o Pull Request está aberto, os teus colegas podem deixar comentário e sugestões. Se decideres alterar alguma coisa, basta fazê-lo no mesmo branch e, quando terminares, fazeres o git push normal. O GitHub adicionará automaticamente os novos commits ao teu Pull Request.
Quando o teu Pull Request for aprovado podes fazer merge. Podes escolher uma de três opções para o fazer (é importante para a organização do repositório que toda a equipa use a mesma opção):
- Create a merge commit: esta é o equivalente a fazer
git merge, mantém todos os commits e deixa intacta o histórico do repositório; - Squash and merge: esta opção altera a história do repositório: se tiveres mais do que um commit no teu branch, esta opção junta-os todos num único commit, fazendo depois um merge normal. Esta é uma opção interessante porque, durante o desenvolvimento, muitas vezes fazemos commits pequenos que não importam na escala do projeto e que tornariam difícil a consulta do histórico do ´master´, devido à sua quantidade, sendo substituídos por um único commit que engloba toda a funcionalidade.
- Rebase and merge: também é uma opção interessante e também altera a história do repositório. No entanto, é uma opção mais avançada que não está no escopo deste guião.
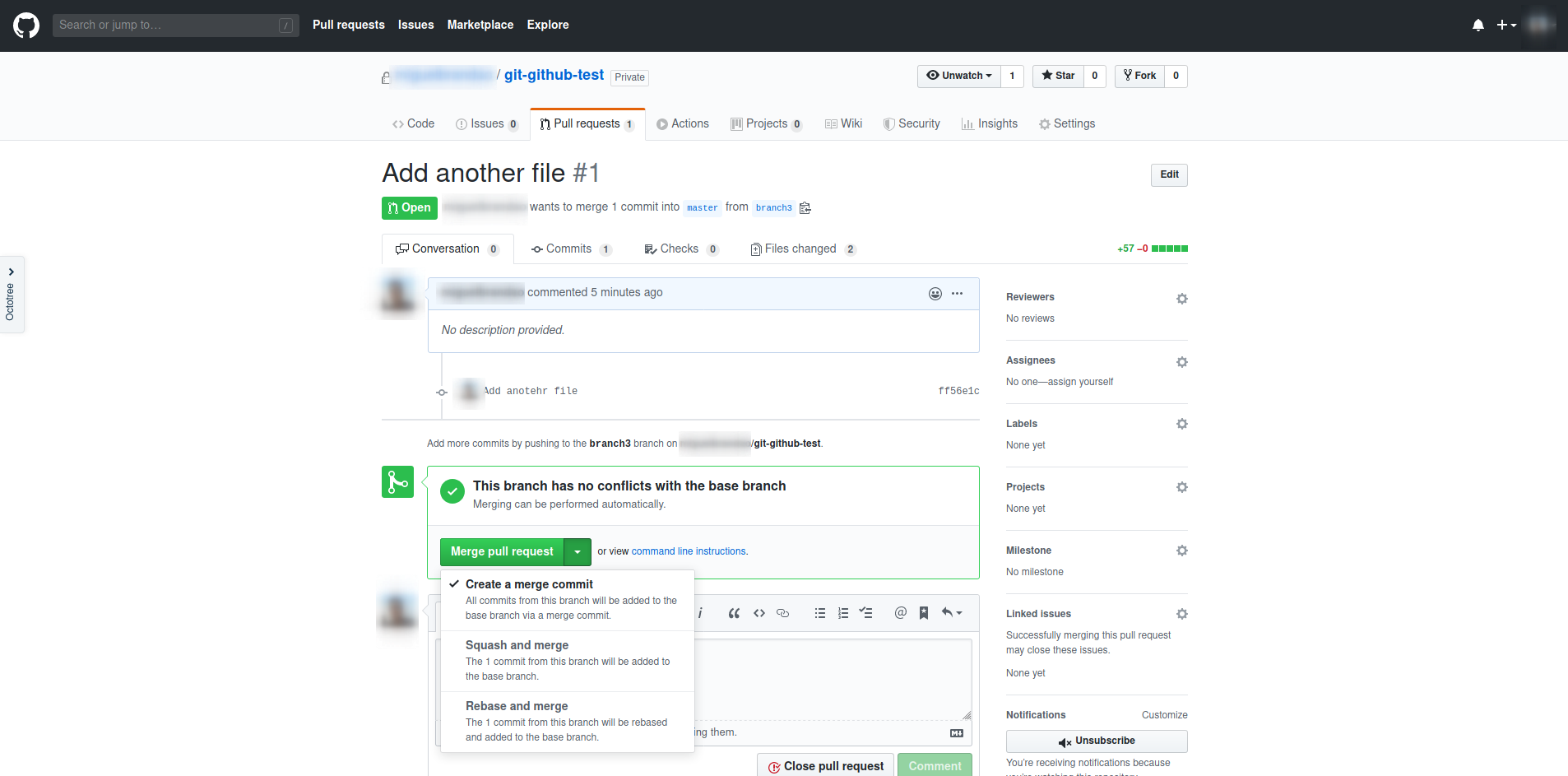
E pronto! As tuas alterações fazem parte do master. Assim, se já não precisares dele, podes eliminar o branch remoto (o teu branch local não é eliminado, tal só pode ser feito por ti no teu PC).
Conclusão
O mundo do Git é imenso, mas agora, se chegaste até aqui, deves conseguir pelo menos ter uma noção de como funciona e como pode melhorar a tua vida enquanto estudante de MIEI e futuro software developer.
Há muitos sites onde podes aprender e muitas ferramentas que podes instalar para melhorar a forma como interages com o Git e o GitHub, é só procurar :)
Este site, por exemplo, é forma engraçada de aprenderes e praticares um pouco de forma interativa.
Se adoraste este guia, se o destestaste, se tens críticas construtivas ou ideias que o possam melhorar, podes-nos contactar diretamente por email (pedagogico@cesium.uminho.pt).